主要內容
_下載XML格式資料、存檔並用ElementTree解析
_網頁資料擷取與beautifulsoup4套件
1.下載XML格式資料、存檔並用ElementTree解析
透過requests模組取得政府公開資訊的xml格式資料並在本機存檔
再利用xml.etree模組的ElementTree函式來解析xml檔案
解析之後的資料在python是字典型態
因此,可以用字典的方式來取得裡面的資料,key-標籤,value-標籤內容
新北市公共自行車租賃系統(YouBike)的xml架構
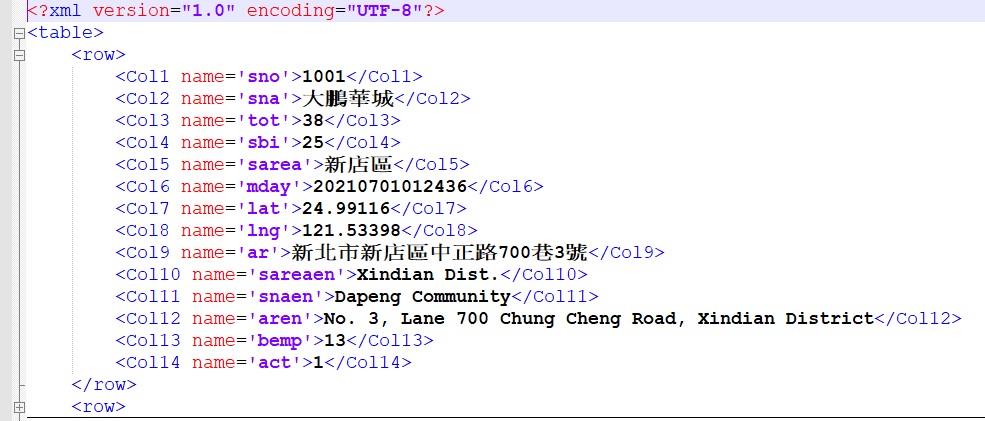
root節點-table
-row
-Col1...
資料都在row節點內的Col1~Col14標籤內容
取出標籤內容是取得text屬性值
取出值之後就可以轉存成csv檔或者excel檔了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
import requests html = requests.get("https://quality.data.gov.tw/dq_download_xml.php?nid=123026&md5_url=4d8de527a0bcd8a7b1aeae91120f021d") f1=open("youbike.xml",'w',encoding="utf-8") f1.write(html.text) f1.close() from xml.etree import ElementTree as ET obj=ET.parse("youbike.xml") youbike_root = obj.getroot() # print(len(youbike_root)) s="sno(站點代號),sna(中文場站名稱),tot(場站總停車格)\n" for youbike_row in youbike_root: s+="{},{},{}\n".format(youbike_row[0].text,youbike_row[1].text,youbike_row[2].text) #print(s) #轉存為csv f2=open("youbike.csv","w",encoding="UTF-8") f2.write(s) f2.close() cols=["sno(站點代號)","sna(中文場站名稱)","tot(場站總停車格)"] data=[] index=[] for i in range(0,len(youbike_root)): data.append([youbike_root[i][0].text,youbike_root[i][1].text,youbike_root[i][2].text]) index.append(i+1) import pandas as pd df = pd.DataFrame(data,index,cols) #print(df) df.to_excel("youbike.xlsx") |
2.網頁資料擷取與beautifulsoup4套件
使用beautifulsoup4模組解析網頁內容
比較常使用find() 或 find_all()來取得標籤資料
find()會取得第一個符合條件的標籤資料
find_all()會取得所有符合條件的標籤資料,並存成串列型態
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
html=""" <html> <head> <meta charset="utf-8"/> <title>Hello</title> </head> <body> <p>Hello World4</p> <p>Hello World2</p> <p>Hello World3</p> </body> </html> """ #-------------------------- from bs4 import BeautifulSoup sp = BeautifulSoup(html, "html.parser") print(sp.find("p")) #包含標籤 print(sp.find("p").text) print(sp.find_all("p")) #串列型態 list1=sp.find_all("p") for i in range(len(list1)): print(list1[i].text) |